主成分分析即Principal Component Analysis,PCA,它是一种线性降维方法。
主成分分析(1)
PCA即主成分分析(Principe Component Analysis)。PCA假设降维函数是一个linear function,即输入$x$和输出$z$之间是linear transform $z=Wx$,而PCA要做的就是根据很多个$x$找出$W$。
PCA for 1-D
为了简化问题先假设输出$z=W\cdot x$是1个标量(scalar),其中$W$是1个行向量(row vector)、$x$是1个列向量。若假设$W$的模(长度)$||W||_2=1$,此时$z$就是$x$在$W$方向上的投影。
我们希望所有$x$在$W$方向上投影得到的所有$z$分布越大越好,也就是说在投影之后不同样本之间的区别仍然是可以被看得出来的,所以投影结果的variance越大越好,即我们希望找到一个使得投影结果的variance较大的$W$,variance的计算公式为$Var(z)=\frac{1}{N}\sum\limits_{z}(z-\bar{z})^2, ||W||_2=1$,其中$\bar z$是所有$z$的平均值。
PCA for n-D
如果输出$z=Wx$是1个包含$n$个元素的向量($n$需要我们自己确定),其中$W$是1个matrix、$w^i$是$W$中的第$i$个行向量($||w^i||_2=0,1\leq i\leq n$)、$x$是1个列向量,则$z_i=w^i\cdot x$表示$x$在方向$w^i$上的投影。
注:$w^i$必须相互正交,即$W$为正交矩阵(Orthogonal Matrix),否则最终找到的$w^i$实际上是相同的值。
拉格朗日乘子法
如何求出PCA中的参数$W$呢?实际上已经有相关库可以直接调用PCA,此外也可以用神经网络描述PCA算法然后用梯度下降的方法来求解,这里主要介绍用拉格朗日乘子法(Lagrange multiplier)求解PCA的数学推导过程。
注:$w^i$和$x$均为列向量,下文中类似$w^i\cdot x$表示的是矢量内积,而$(w^i)^T\cdot x$表示的是矩阵相乘。
计算$w^1$
结论:$w^1$是$S=Cov(x)$这个matrix中的特征向量,对应最大的特征值$\lambda_1$。
首先计算出$\bar{z_1}$:
$Var(z_1)$越大越好,所以我们要使得$Var(z_1)$最大:
因为$(a\cdot b)^2=(a^Tb)^2=a^Tba^Tb=a^Tb(a^Tb)^T=a^Tbb^Ta$,所以:
又因为$Cov(x)=\frac{1}{N}\sum(x-\bar x)(x-\bar x)^T$,并令$S=Cov(x)$,所以:
在使得$Var(z_1)=(w^1)^TCov(x)w^1$最大的同时,还有一个约束条件是$||w^1||_2=(w^1)^Tw^1=1$,否则$w^1$无限大就可以使得$Var(z_1)$但这并没有意义。
因为$S=Cov(x)$,所以S是对称的(symmetric)、半正定的(positive-semidefine)、所有特征值非负的(non-negative eigenvalues)。
使用拉格朗日乘数法,利用目标和约束条件构造函数:$g(w^1)=(w^1)^TSw^1-\alpha((w^1)^Tw^1-1)$,对$w^1$中每个元素求偏微分并使为0:
整理上式,可以得到:$Sw^1=\alpha w^1$,其中$w^1$是$S$的特征向量(eigenvector),但满足$(w^1)^Tw^1=1$的特征向量$w^1$有很多,我们要找的是使得$(w^1)^TSw^1$最大的那个$w_1$,于是可得$(w^1)^TSw^1=(w^1)^T \alpha w^1=\alpha (w^1)^T w^1=\alpha$,因此使得$(w^1)^TSw^1$最大就变成了使得$\alpha$最大,即$S$的特征值$\alpha$最大时对应的那个特征向量$w^1$就是我们要找的$w^1$。
计算$w^2$
在计算$w^2$时比计算$w^1$时多了一个限制条件:$w^2$必须与$w^1$正交(orthogonal)。
所以求解目标为:使得$(w^2)^TSw^2$最大,约束条件为:$(w^2)^Tw^2=1,(w^2)^Tw^1=0$
结论:$w^2$也是$S=Cov(x)$这个matrix中的特征向量,对应第二大的特征值$\lambda_2$
与计算$w^1$一样使用拉格朗日乘子法求解,定义$g(w^2)=(w^2)^TSw^2-\alpha((w^2)^Tw^2-1)-\beta((w^2)^Tw^1-0)$,然后对$w^2$的每个元素做偏微分:
整理上式可得$Sw^2-\alpha w^2-\beta w^1=0$,该式两侧同乘$(w^1)^T$得到$(w^1)^TSw^2-\alpha (w^1)^Tw^2-\beta (w^1)^Tw^1=0$,其中$\alpha (w^1)^Tw^2=0,\beta (w^1)^Tw^1=\beta$。
由于$(w^1)^TSw^2$是vector×matrix×vector=scalar所以在外面套一个transpose不会改变其值,并且S是对称的即$S^T=S$,所以:
已知$w^1$满足$Sw^1=\lambda_1 w^1$,所以:
因此有$(w^1)^TSw^2=0$,$\alpha (w^1)^Tw^2=0$,$\beta (w^1)^Tw^1=\beta$,又根据$(w^1)^TSw^2-\alpha (w^1)^Tw^2-\beta (w^1)^Tw^1=0$,所以$\beta=0$。
此时$Sw^2-\alpha w^2-\beta w^1=0$就转变成了$Sw^2-\alpha w^2=0$即$Sw^2=\alpha w^2$。由于$S$是对称的,因此在与$w_1$不冲突的情况下,这里$\alpha$选取第二大的特征值$\lambda_2$时,可以使$(w^2)^TSw^2$最大。
decorrelation
可知$z=W\cdot x$,有一个神奇的事情是$Cov(z)=D$,即z的covariance是一个对角矩阵(diagonal matrix)。
推导过程如下:
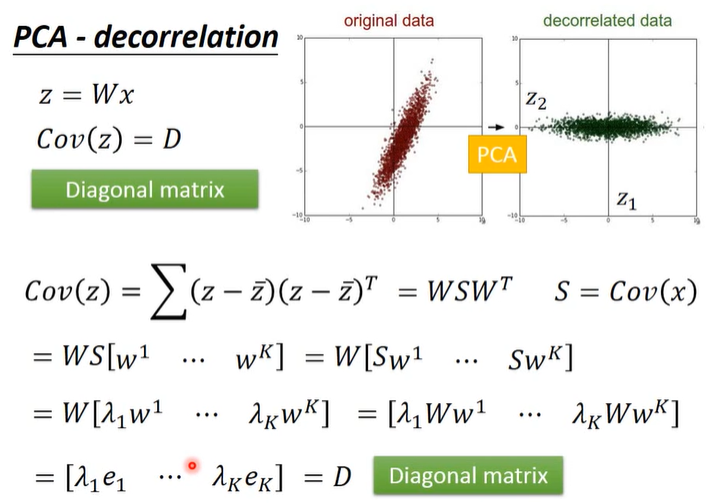
PCA可以让降维后数据中不同dimension之间的covariance变为0,即降维后数据中不同feature之间是没有correlation的,这样的好处是减少feature之间的联系从而减少model所需的参数量。
如果使用PCA将原数据降维之后再给其他model使用,那这些model就可以直接假设数据的各个维度不相关,这时model得到简化、参数量大大降低,相同的数据量可以得到更好的训练结果,从而可以避免overfitting的发生。
主成分分析(2)
Reconstruction Component
假设我们现在考虑MNIST手写数字识别,可以假设一个数字图片由一些类似于笔画的component(本质上是一个28×28的vector)组成,将这些component记做$u_1,u_2,u_3,…$,我们把$K$个component加权求和就可以组成一个数字图片:$x≈c_1u^1+c_2u^2+…+c_Ku^K+\bar x$,其中$x$是一张数字图片,$\bar x$是所有数字图片的平均值。
假设$K$个component已知,我们就可以用$\left [\begin{matrix}c_1\ c_2\ c_3…c_k \end{matrix} \right]^T$来表示一张数字图片,如果$k$远小于图片像素数量,那这种表示方法就可以有效降维。
那我们要如何找出这$K$个component呢?我们要找到$K$个vector使得$x-\bar x$和$\hat x$越接近越好,其中$\hat x=c_1u^1+c_2u^2+…+c_Ku^K$。
所以目标是使得Reconstruction Error $||(x-\bar x)-\hat x||$最小,即$L=\min\limits_{u^1,…,u^k}\sum||(x-\bar x)-(\sum\limits_{i=1}^k c_i u^i) ||_2$。
回顾PCA中$z=W\cdot x$,实际上我们通过PCA最终解得的$W=\{w^1,w^2,…,w^k\}$就是使Reconstruction Error最小化的$K$个vector$\{u^1,u^2,…,u^k\}$,简单证明如下。
如下图和下式所示,用下图中的矩阵相乘来表示所有的$x^i-\bar x≈c_1^i u^1+c_2^i u^2+…$,其中$x^i$指第$i$张图片,目标是使$\approx$两侧矩阵之间的差距越小越好。
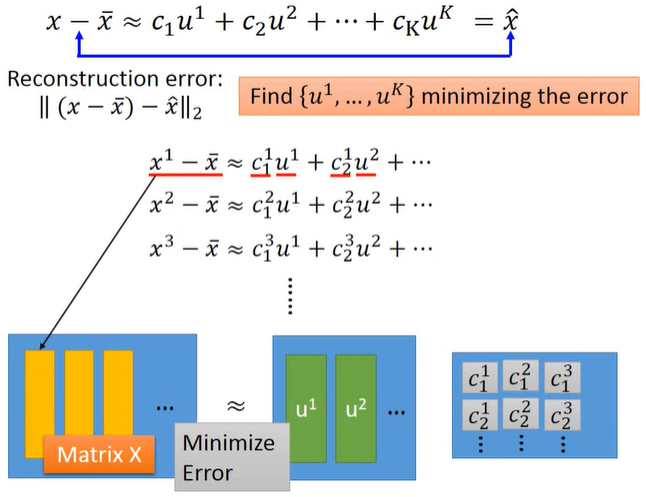
使用SVD将每个matrix $X_{m×n}$都拆成matrix $U_{m×K}$、$\Sigma_{K×K}$、$V_{K×n}$的乘积,其中$K$为component的数目。使用SVD拆解后三个矩阵相乘的结果是跟等号左边的矩阵$X$最接近的,此时$U$就对应着$u^i$形成的矩阵、$\Sigma\cdot V$就对应着$c_k^i$形成的矩阵。
根据SVD的结论,组成矩阵$U$的$k$个列向量(标准正交向量,orthonormal vector)就是$XX^T$最大的$k$个特征值(eignvalue)所对应的特征向量(eigenvector),而$XX^T$实际上就是$x$的covariance matrix,因此$U$就是PCA的$k$个解。
PCA寻找$W$的过程,实际上就是把$X$拆解成能够使得Reconstruction Error最小的$k$个component的过程,PCA中要找的投影方向$w^i$就相当于恰当的component $u^i$,PCA中投影结果$z^i$就相当于各个component各自的权重$c_i$。
NN for PCA
由上可知,PCA找出来的$\{w^1,w^2,…,w^k\}$就是$K$个component $\{u^1,u^2,…,u^k\}$。$\hat x=\sum\limits_{k=1}^K c_k w^k$,我们要使$\hat x$与$x-\bar x$之间的差距越小越好。我们已经通过SVD找到了$w^k$的值,而对每个不同的样本$x$都有一组不同的$c_k$值。
在PCA中我们已经证得,$\{w^1,w^2,…,w^k\}$这$k$个vector是标准正交化的(orthonormal),因此$c_k=(x-\bar x)\cdot w^k$,这个时候我们就可以使用神经网络来表示整个过程,如下图所示。
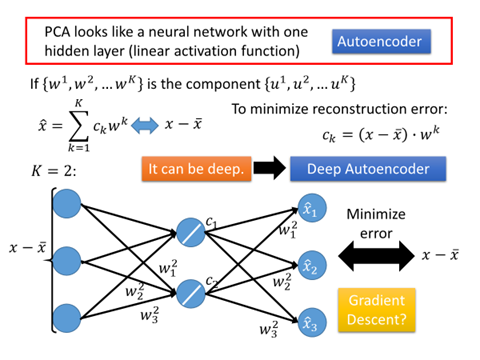
如上图所示,假设$x$是3维向量,要投影到2维的component上,即$K=2$。$c_k=(x-\bar x)\cdot w^k$类似于神经网络,$x-\bar x$相当于一个神经元的3维输入,而$w^k_1$,$w^k_2$,$w^k_3$则是该神经元的权重,而$c_k$则是这个神经元的输出。得到$c_1$和$c_2$之后,再让它乘上$w^1$和$w^2$然后求和得到$\hat x$。此时,PCA就被表示成只含一层hidden layer的神经网络,且这个hidden layer是线性的(没有激活函数),训练目标是让这个神经网络的输入$x-\bar x$与输出$\hat x$越接近越好,这就是Autoencoder。
注:PCA求解出的$w^i$与上述神经网络所解得的$w^i$是不一样的,因为PCA解出的$w^i$是相互垂直的(orgonormal),而上述神经网络的解无法保证$w^i$相互垂直,神经网络无法做到Reconstruction Error比PCA小。因此,在linear情况下直接用PCA找$W$远比用神经网络的方式更快速方便,神经网络的好处是它可以使用不止一层的hidden layer而可以做Deep Autoencoder。
PCA的缺点
- PCA是无监督的,没有使用label
- PCA是线性的,而有时需要non-linear transformation
What happens to PCA
观察PCA对MNIST和Face的降维结果(见原视频),我们发现找到的component好像并不算是component。比如MNIST实验中PCA找到的是几乎完整的数字雏形,而Face实验中找到的是几乎完整的人脸雏形,而我们想象中的组件应该是类似于横折撇捺、眼睛鼻子眉毛等等。
原因是这样的:$x\approx c_1u^1+c_2u^2+…+c_Ku^K+\bar x$,其中$c_i$是可正可负的,所以component不仅可以相加还可以相减,于是PCA得到的组件并不是我们想象中的那样,但通过这些组件的加加减减肯定可以获得我们想象中的基础的component。
如果想要直接得到类似笔画的基础component,就要使用NMF(non-negative matrix factorization,非负矩阵分解)。
非负矩阵分解
如果想要直接得到类似笔画的基础component,就要使用NMF(non-negative matrix factorization,非负矩阵分解)。
PCA可以看成是对原始矩阵$X$做SVD进行矩阵分解,但并不保证分解后矩阵的正负。实际上在进行图像处理时,如果部分component的matrix包含一些负值的话,如何处理负的像素值也会成为一个问题(可以做归一化处理,但比较麻烦)。
而NMF的基本思路是,强迫使所有component和它的权重都必须是正的,也就是说所有图像都必须由组件叠加(不可相减)得到。
相比于PCA,我们可以发现NMF对MNIST和Face的降维结果(见原视频)更接近于我们想象中的基本的component。
其它PCA版本
降维的方法有很多,这里再列举一些与PCA有关的方法:
Multidimensional Scaling (MDS) [Alpaydin, Chapter 6.7]
MDS不需要把每个data都表示成feature vector,只需要知道特征向量之间的distance,就可以做降维,PCA保留了原来在高维空间中的距离,在某种情况下MDS就是特殊的PCA
Probabilistic PCA [Bishop, Chapter 12.2]
PCA概率版本
Kernel PCA [Bishop, Chapter 12.3]
PCA非线性版本
Canonical Correlation Analysis (CCA) [Alpaydin, Chapter 6.9]
CCA常用于两种不同的data source的情况,比如同时对声音信号和唇形的图像进行降维
Independent Component Analysis (ICA)
ICA常用于source separation,PCA找的是正交的组件,而ICA则只需要找“独立”的组件即可
Linear Discriminant Analysis (LDA) [Alpaydin, Chapter 6.8]
LDA是supervised的方式
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!