transformer最知名的应用就是BERT,BERT就是无监督训练的transformer,transformer就是具有Self-attention的Seq2Seq模型。
RNN常用于处理输入和输出都是sequence的任务,因为RNN是通过遍历输入的sequence而逐步输出一个sequence,所以RNN很难被并行化。因为CNN可以并行化,所以有人提出用CNN处理输入和输出是sequence的任务:每个卷积核将sequence中的一部分作为输入并输出一个sequence、多个卷积核就可以生成多个sequence。层数较少的CNN不能看到long-term的信息,层数很多的CNN才能看到long-term的信息,如果在浅层(比如第一层)就需要看到long-term的信息怎么办呢?
有人提出用Self-Attention Layer代替RNN,其输入和输出和RNN一样都是sequence,它的特别之处是和Bidirectional RNN一样在输出时就已经看过了输入的整个sequence,并且可以并行计算。
Self-Attention
Self-Attention来自于谷歌的paper:《Attention is all you need》。
假设现在有输入序列$x^1,x^2,x^3,x^4$
进行embedding:$a^i=Wx^i$
将$a^i$输入到Self-Attention Layer得到$q^i,k^i,v^i$
$q$代表query,它是要去和key进行match的,$q^i=W^qa^i$
$k$代表key,它是要被query进行match的,$k^i=W^ka^i$
$v$代表value,我们要通过attention从中进一步提取information,$v^i=W^va^i$
使用每个query对每个key做attention
以$q^i$为例,使用$q^i$和4个key得到$\alpha_{i,1},\alpha_{i,2},\alpha_{i,3},\alpha_{i,4}$,可以使用Scaled Dot-Product Attention:$\alpha_{i,j}=\frac{q^i\cdot k^j}{\sqrt d}$,其中$d$是$q^i$和$k^j$的维数,除以$\sqrt d$是因为$q^i\cdot k^j$的大小会受$d$的大小的影响;再使用softmax函数得到$\hat\alpha_{i,1},\hat\alpha_{i,2},\hat\alpha_{i,3},\hat\alpha_{i,4}$
$b^i=\sum\limits_j\hat\alpha_{i,j}v^j$,这样在计算$b^i$时就是可以看到输入的整个sequence
Self-Attention如何并行化计算
Self-Attention是如何实现并行化计算的呢?上述Self-Attention的计算其实都是一些矩阵运算,因此可以使用GPU加速。
- 输入为$I$
- $Q=W^qI,K=W^kI,V=W^vI$
- $A=K^TQ$
- $\hat A=softmax(A)$
- 输出为$O=V\hat A$
Multi-head Self-attention
Self-attention有一种变形是Multi-head Self-attention,现以2个head的情况为例介绍Multi-head Self-attention。
Multi-head的作用在于不同head关注的东西可能不一样。
假设现在有输入序列$x^1,x^2,x^3,x^4$
进行embedding:$a^i=Wx^i$
将$a^i$输入到Self-Attention Layer得到$q^{i,1},q^{i,2},k^{i,1},k^{i,2},v^{i,1},v^{i,2}$
这里体现了Multi-head。
$q$代表query,它是要去和key进行match的,$q^{i,1}=W^{q,1}a^i,q^{i,2}=W^{q,2}a^i$
$k$代表key,它是要被query进行match的,$k^{i,1}=W^{k,1}a^i,k^{i,2}=W^{k,2}a^i$
$v$代表value,我们要通过attention从中进一步提取information,$v^{i,1}=W^{v,1}a^i,v^{i,2}=W^{v,2}a^i$
使用每个query对每个key做attention
这里体现了Multi-head。
以$q^{i,1},q^{i,2}$为例,$q^{i,1}$只会和$k^{i,1}$做attention,$q^{i,2}$只会和$k^{i,2}$做attention
最终得到$b^{i,1},b^{i,2}$,将两者直接concat,如果需要还可以通过乘以$W^O$修改维度
Positional Encoding
上面讲的Self-Attention并没有考虑sequence中元素之间的顺序,所以需要Positional Encoding。
Positional Encoding即每个position都有一个独一无二的positional vector $e^i$,这些vector并不是从数据中学习到的,在将$x^i$embedding得到$a^i$后再加上$e^i$,然后再输入到Self-Attention Layer。
Seq2Seq with Attention
如何将Self-Attention应用到一个Seq2Seq模型中呢?
一般的Seq2Seq模型中包括2个RNN分别作为Encoder和Decoder,我们可以使用Self-Attention Layer代替这2个RNN。
Transformer
以中文翻译为英文的任务为例,假如要把“机器学习”翻译为“Machine Learning”。
Transformer也分为Encoder和Decoder,Encoder的输入是“机器学习”,先给Decoder一个输入<BOS>代表句子的开始(begin of sentence),然后Decoder会输出一个“Machine”,在下一个时刻把“Machine”输入到Decoder得到“Learning”,直到Decoder输出“句点”。
下面介绍Transformer的具体结构,如下图所示。
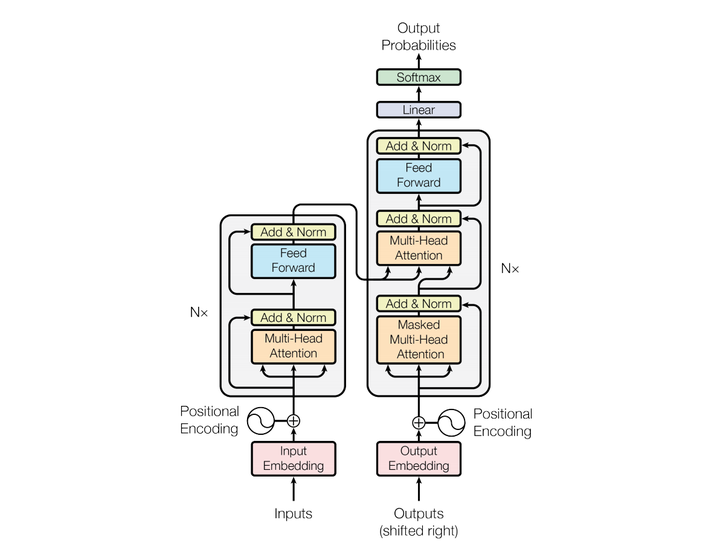
如上图所示,在Encoder中,首先将输入进行embedding,然后加上positional encoding,然后进入多个相同的Block。每个Block中首先是一个Multi-head Attention,然后再将Multi-head Attention的输入和输出加起来,然后做Layer Normalization,然后进入Feedforward Layer,再将Feedforward Layer的输入和输出加起来,然后做Layer Normalization。
如上图所示,在Decoder中,Decoder的输入是Decoder在前一个时刻的输出,然后加上positional encoding,然后进入多个相同的Block。每个Block中首先是一个Masked Multi-head Attention(Masked指Decoder在做Self-Attention时只会attend已经生成的sequence),然后将Masked Multi-head Attention的输入和输出加起来,再做Layer Normalization,然后将Layer Normalization的输出和Encoder的输出输入到一个Multi-head Attention中,然后将Multi-head Attention的输入和输出详见并做Layer Normalization,然后进入Feedforward Layer,再将Feedforward Layer的输入和输出加起来,然后做Layer Normalization。多个相同的Block结束以后,进入Linear层,然后进入Softmax层得到最终的输出。
如果一个任务可以用Seq2Seq模型完成,那就可以用Transformer。
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!