分类模型应用案例(Classification Cases)
- 信用评分(Credit Scoring)
- 输入:收入、储蓄、职业、年龄、信用历史等等
- 输出:是否贷款
- 医疗诊断(Medical Diagnosis)
- 输入:现在症状、年龄、性别、病史
- 输出:哪种疾病
- 手写文字识别(Handwritten Character Recognition)
- 输入:文字图片
- 输出:是哪一个汉字
- 人脸识别(Face Recognition)
- 输入:面部图片
- 输出:是哪个人
把分类当成回归去做?
不行。
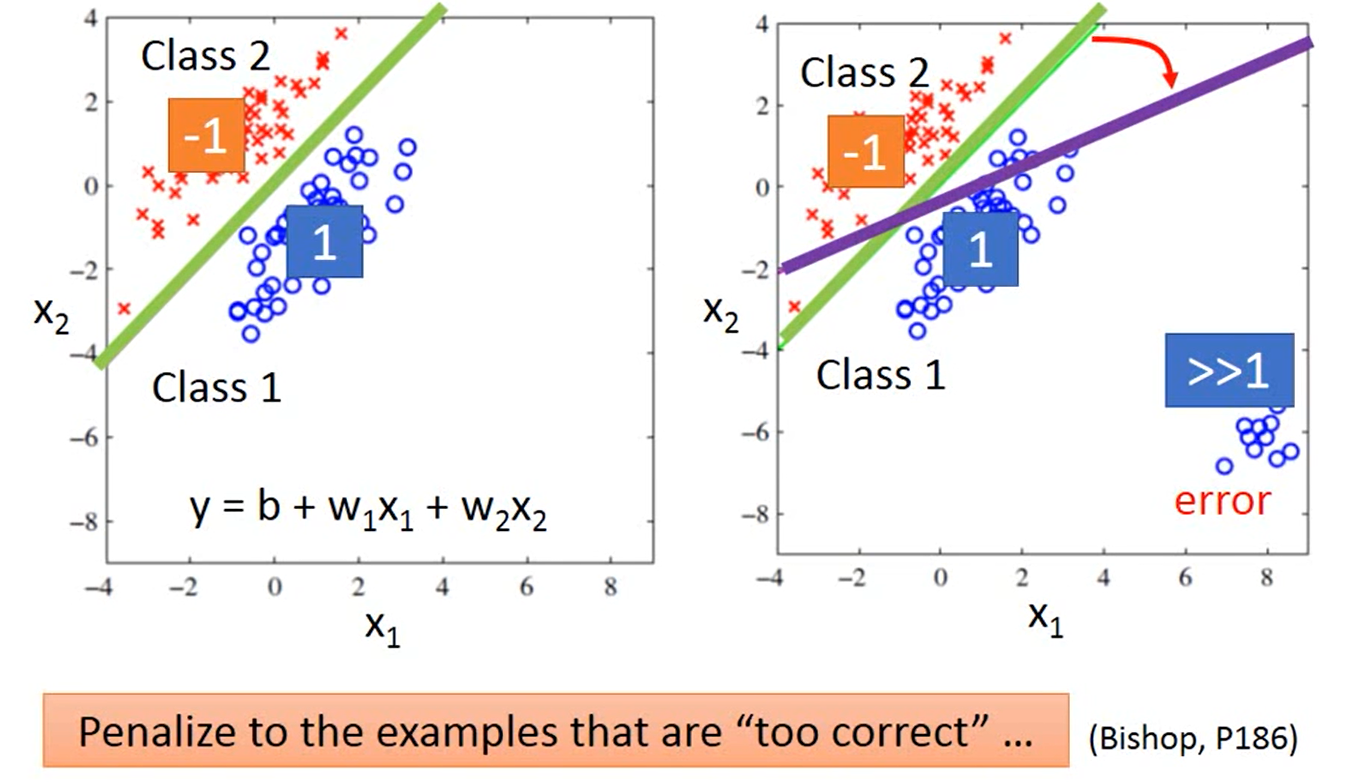
假设有两个类别,其中类别1的标签为1,类别2的标签为-1,那0就是分界线,大于0就是类别1,小于0就是类别2。
回归模型会惩罚那些太正确的样本。如果结果远远大于1,它的分类应该是类别1还是类别2?这时为了降低整体误差,需要调整已经找到的回归函数,就会导致结果的不准确。
假设有多个类别,类别1的标签是1,类别2的标签是2,类别3的标签是3。
这样的话,标签间具有2和3相近、3大于2这种本来不存在的数字关系。
理想替代方案(Ideal Alternatives)
模型
模型可以根据特征判断类型,输入是特征,输出是类别
损失函数
预测错误的次数,即$L(f)=\sum_n\delta(f(x^n)\neq\hat y^n)$。
这个函数不可微
如何找到最好的函数
比如感知机(Perceptron)、支持向量机(SVM)
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!