Boundary Aware PoolNet = PoolNet + BASNet,即使用BASNet中的Deep Supervision策略和Hybrid Loss改进PoolNet。
前面两篇文章分别介绍了PoolNet的模型及其代码、BASNet中的深度监督策略和混合损失函数,现在让我们看向PoolNet,使用BASNet一文提出的Deep Supervision和Hybrid Loss,形成BAPoolNet(Boundary Aware PoolNet)。
本文将详细介绍如何使用BASNet中的的Deep Supervision和Hybrid Loss改进PoolNet得到BAPoolNet,并介绍我在研究BAPoolNet时观察到的一些现象和结论。
相关文章汇总:
BAPoolNet结构
在PoolNet中Backbone是ResNet50时,模型自顶向下路径中有5个FUSE操作,我借鉴BASNet中的Deep Supervision和Hybrid Loss使用这5层输出的混合Loss之和进行梯度下降,我将这整个模型称为BAPoolNet(Boundary Aware PoolNet),其结构如下图所示。
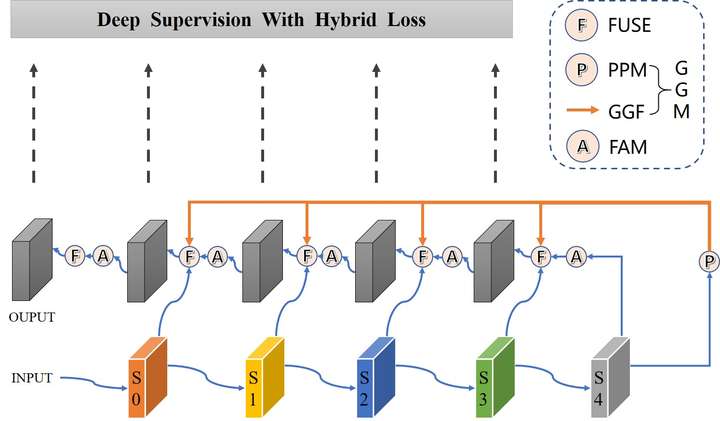
与PoolNet相比,BAPoolNet的不同之处为:
- 添加5个边路输出以进行Deep Supervision
- 在计算Loss时使用BCE损失、SSIM损失、IOU损失之和
如何实现Boundary Aware PoolNet,具体请看代码。
BAPoolNet训练
训练设置
本文使用DUTS数据集进行模型训练和测试,其训练集包含10553张图片、测试集包含5019张图片。
除了对PoolNet的改进之外,BAPoolNet的其它实现细节和实验细节和PoolNet保持一致。
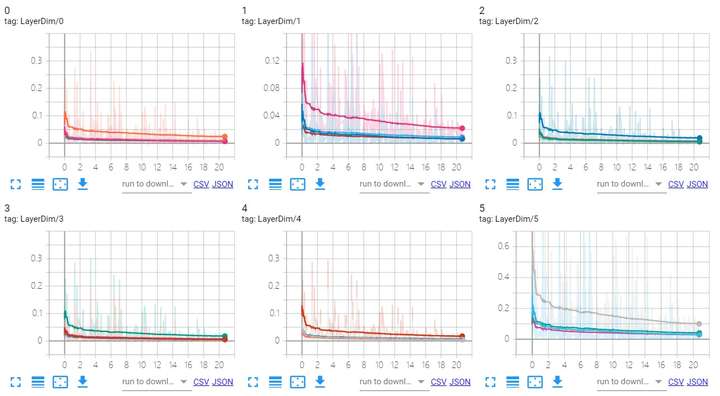
训练过程中五个边路输出损失的变化情况
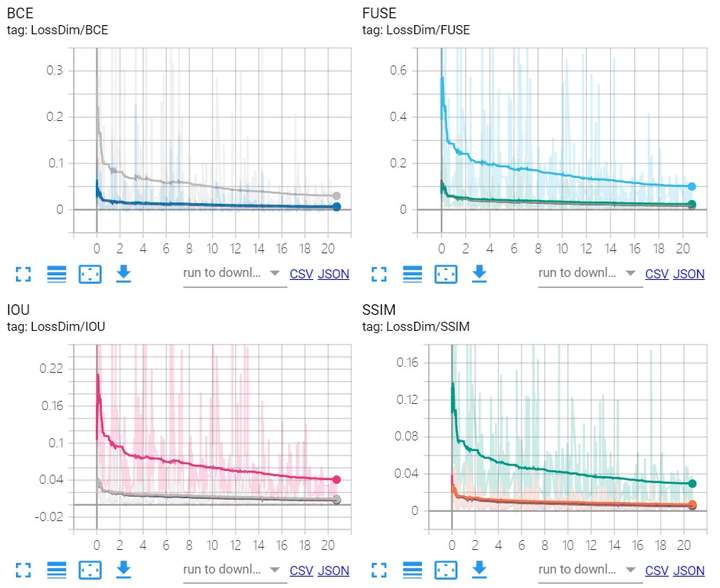
训练过程中三种损失的变化情况
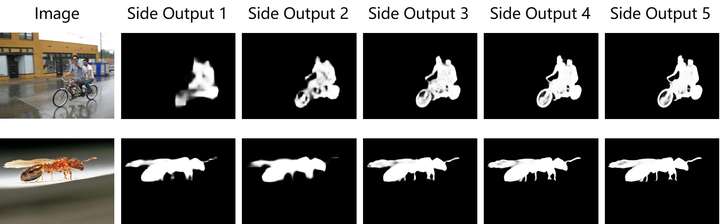
5个边路输出可视化结果
训练过程中MAE的变化情况
下图为在DUTS-TE数据集上的测试结果。
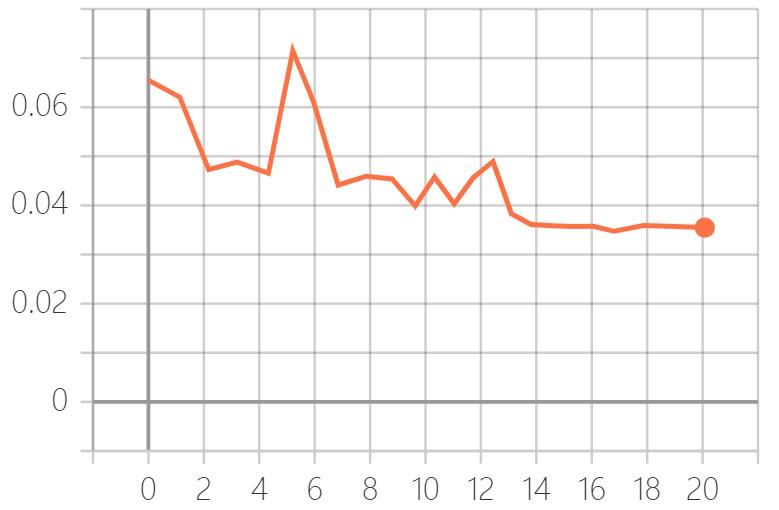
训练过程中F-measure的变化情况
下图为在DUTS-TE数据集上的测试结果(二值化阈值为0.5)。
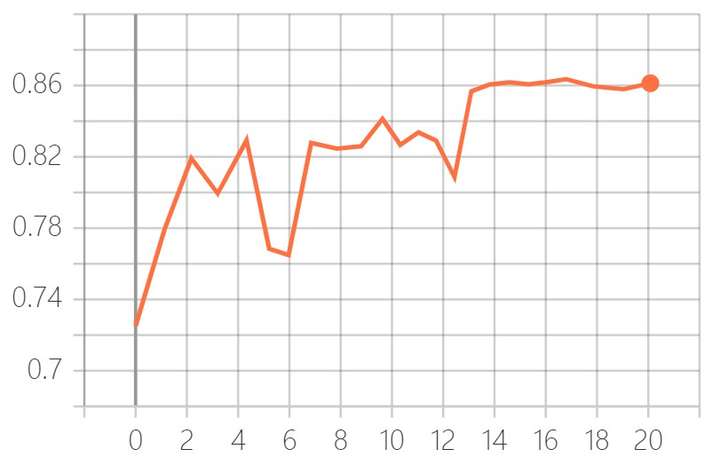
BAPoolNet性能
视觉对比

量化对比
下表中MAE和maxF为各方法在DUTS-TE数据集上的测试结果。
| Method | Conference | Backbone | Size(MB) | MAE↓ | maxF↑ |
|---|---|---|---|---|---|
| CapSal | CVPR19 | ResNet-101 | - | 0.063 | 0.826 |
| PiCANet | CVPR18 | ResNet-50 | 197.2 | 0.050 | 0.860 |
| DGRL | CVPR18 | ResNet-50 | 646.1 | 0.049 | 0.828 |
| BASNet | CVPR19 | ResNet-34 | 348.5 | 0.047 | 0.860 |
| U2Net | CVPR20 | RSU | 176.3 | 0.044 | 0.873 |
| CPD | CVPR19 | ResNet-50 | 183.0 | 0.043 | 0.865 |
| PoolNet | CVPR19 | ResNet-50 | 260.0 | 0.040 | 0.880 |
| BAPoolNet | - | ResNet-50 | 260.7 | 0.035 | 0.892 |
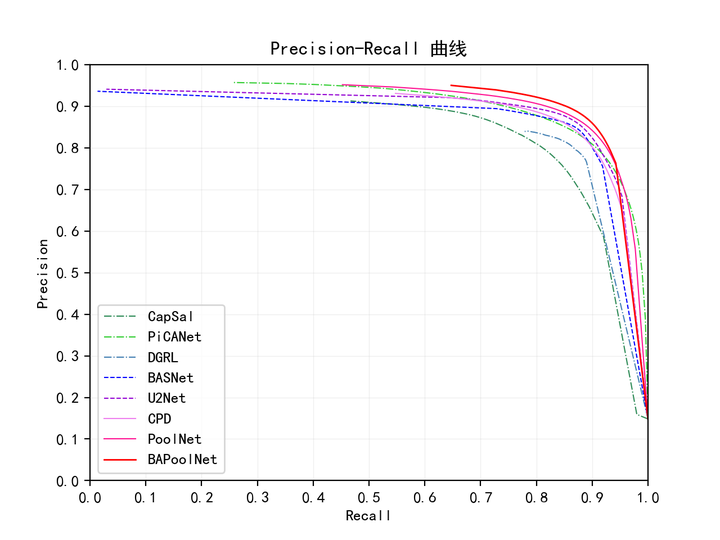
PR曲线
下图为各方法在DUTS-TE数据集上的测试结果。
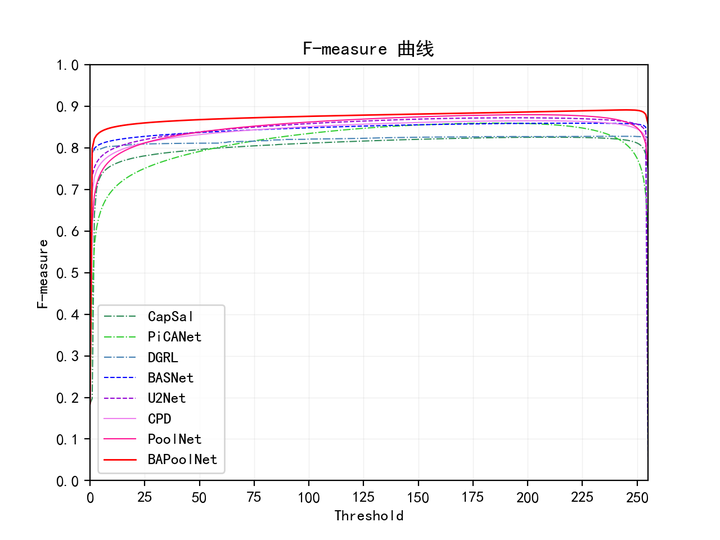
F-measure曲线
下图为各方法在DUTS-TE数据集上的测试结果。
BAPoolNet代码
传送门(Boundary Aware PoolNet代码):https://github.com/chouxianyu/Boundary-Aware-PoolNet
相比于PoolNet,BAPoolNet代码的改动之处有:
BCE Loss计算方法
设置为
reduction=mean而非reduction=sum,并且用sigmoid+BCE代替F.binary_cross_entropy_with_logits。PoolNet
forward()返回结果PoolNet类返回了5个边路输出而非最终输出
整体Loss计算方法
使用Hybrid Loss和Deep Supervision计算整体Loss
模型性能评估代码(MAE、F-measure等),我参考了:https://github.com/Hanqer/Evaluate-SOD
除了对PoolNet的改进之外,BAPoolNet的其它实现细节和实验细节和PoolNet保持一致。
实验细节
“黑图片”问题
在训练模型时,如果模型使用train()模式,结果反而比eval()差,具体现象为使用train()模式时,预测结果中有大量“黑图片”,即图片中的像素几乎都是黑色的。
浅/深层的作用
将5个边路输出可视化,可以看出0层的主要作用是定位显著目标,而后几层的主要作用是细化显著目标的特征,即在自顶向下路径中显著目标的细节逐渐丰富,同时这也代表着当浅层无法准确定位显著目标时最终输出也就无法准确定位显著目标。
我尝试过在计算5层Loss之和时调整不同层Loss的权重,比如第1层Loss权重为5、其它4层Loss权重为1或者前4层Loss权重为1、最后1层Loss权重为10等等,评估指标(MAE、F-meausure)显示调整不同层Loss权重的做法对性能提升并没有什么作用。
既然自顶向下路径中浅层富含高级语义信息/局部细节信息较少、深层高级语义信息相对较少/局部细节信息丰富,我想也许可以利用这一点在不同层使用不同的损失函数。(学识尚浅,也许这样并无效果)
其它
基于Deep Supervision+Hybrid Loss,我还做了一些更具体的尝试,结果如下:
- 将
F.binary_cross_entropy_with_logits换为sigmoid+BCE对结果并没有什么影响,虽然官方也说了两者仅在计算上有细微差别。 - 若只使用BCE Loss,则
reduction=mean和reduction=sum在训练效果上差别不大,只是两者所得Loss数值的数量级有所差异,前者Loss的数量级为0到10,后者Loss的数量级在1000到几万。 - 在计算边路输出时使用3×3卷积或者1×1卷积,评估所得模型,MAE、F-measure等差别不大。
- 调整不同层Loss的权重对模型性能不大。
- 调整学习率对模型性能影响不大。
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!