Universal Adversarial Attack
Attack可以是分别为每个输入$x^0$找到对应的攻击信号$\Delta x$,还可以是找到一个适用于所有输入的攻击信号$\Delta x$,这就是Universal Adversarial Attack,详见:Universal adversarial perturbations(https://arxiv.org/abs/1610.08401)。
One Pixel Attack
One Pixel Attack就是攻击时的constraint为只能修改图片中一个pixel,即$d(x^0,x’)=||x^0-x’||_0=||\Delta x||_0\leq1$,其中可以将L0范数理解为非零元素的个数。
如何确定要攻击哪个像素呢?暴力求解速度会很慢。还有个问题是我们是否需要最佳的攻击方案?如果能够使用Loss梯度下降找到最佳的攻击方案,那当然是好的,但其实我们只需攻击成功即可,因为攻击的目标主要是使模型失效,只要可以攻击成功就行。比如原模型对某图片的分类结果是置信度为16.48%的Cup,我们能找到一个方案使模型分类结果是置信度为16.74%的Soup Bowl即可而不需要必须使得置信度为100%。同理,我们只要能找到某个可以击破的像素就行而并不需要找到最薄弱的像素。
那如何找到一个攻击方案呢?用Differential Evolution就行。Differential Evolution的好处是有较大的概率得到全局最优解并且不需要计算梯度也就不需要被攻击模型的参数。Differential Evolution与遗传算法非常类似,都包括变异、杂交和选择操作,但这些操作的具体定义与遗传算法有所不同。
详见One pixel attack for fooling deep neural networks(https://arxiv.org/abs/1710.08864)。
Adversarial Reprogramming
我们可以在不改变模型参数的情况下,通过Attack来修改模型的“功能”,比如将一个图片分类模型的功能改为方块计数(方块数量对应某种种类),详见:
- Adversarial Reprogramming of Neural Networks(https://arxiv.org/abs/1806.11146v2)
- https://arxiv.org/abs/1705.09554
- https://arxiv.org/abs/1707.05572
Attack in the Physical World
有一个问题是,我们说的这些攻击在物理世界中会失效吗?比如相机等设备会不会像人一样无法识别那些攻击信号呢?答案是不一定。有人做了相关实验,将扰动得到的图片$x’$打印出来,然后用手机、相机等拍照再做分类或识别,仍然可以成功攻击模型,详见:Adversarial examples in the physical world(https://arxiv.org/abs/1607.02533v4)、https://www.youtube.com/watch?v=zQ_uMenoBCk&feature=youtu.be
攻击还可以用在人脸识别领域,比如我戴一个实体眼镜(用于攻击)之后可能就会被人脸识别系统识别为其他人,详见:https://www.cs.cmu.edu/~sbhagava/papers/face-rec-ccs16.pdf
攻击还可以用在自动驾驶中,假如汽车在自动驾驶时需要看红绿灯等标志物,那在这些标志物上贴一些攻击信号也许就会导致车辆“失控”,详见:https://arxiv.org/abs/1707.08945
Attack Text & Audio
攻击并不仅限于Image,还可以攻击Text,可参考:https://arxiv.org/pdf/1707.07328.pdf
攻击并不仅限于Image和Text,还可以攻击Audio,可参考:
- https://nicholas.carlini.com/code/audio_adversarial_examples
- https://adversarial-attacks.net
- 现实中ASR可能会受到攻击,ASR指Automatic Speech Recognition(自动语音识别),即语音转文字,详见:https://nicholas.carlini.com/code/audio_adversarial_examples/
- ASV也可能会受到攻击,ASV指Automatic Speaker Verification,即识别是谁讲话,详见:https://arxiv.org/abs/1911.01840
Hidden Voice Attack
Hidden Voice Attack就是生成一段人类无法听懂的audio但仍然可以骗过你的模型,比如用一段人类听不懂但被模型判定为“Hey, Siri”的audio启动你的苹果手机。
详见:https://arxiv.org/abs/1904.05734
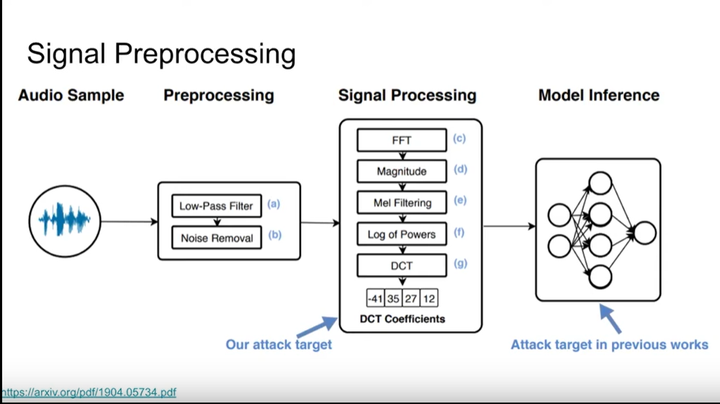
如下图所示,处理audio的步骤为Preprocessing、Signal Processing、Model Inference,Hidden Voice Attack就是在Signal Processing阶段进行攻击。
如下图所示,对audio的扰动方式有4种,具体不再详细介绍。
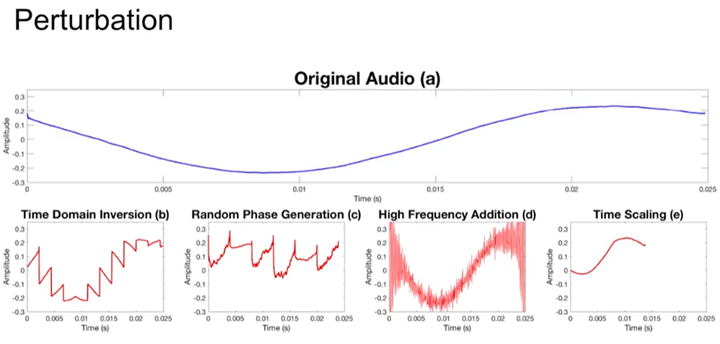
Time Domain Inversion
Time Domain Inversion简称TDI,它利用了magnitude FFT多对一的性质(两个不同的signal经过mFFT可以得到相同结果),所以我们可以将time domain中的signal进行处理,处理之后会影响人听懂但不影响模型。
Random Phase Generation
FFT返回了一个复数$a+bi$,而$magnitude=\sqrt{a^2+b^2}$,不同的$a$和$b$可以计算得到相同的magnitude,所以可以对$a$和$b$进行修改,修改后会影响人听懂但不影响模型。
High Frequency Addition
High Frequency Addition简称HFA。
在Preprocessing过程中会使用low-pass filter过滤掉比人声高很多的频段以增加Voice Processing System的准确率,那我们就可以在audio中加入高频段audio,这样会影响人听懂但不影响模型。
Time Scaling
将audio缩短到model能正确辨识但人听不懂。
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!