在Slot Filling中,输入是1个word vector,输出是每个word的label,输入和输出是等长的。
然而,RNN还可以实现多对1、多对多…
Many to One
Many to One:输入是1个vector sequence,输出是1个vector
Sentiment Analysis
输入1篇文章或1句话等(1个vector sequence),输出其情感倾向(分类或者回归,比如超好、好、普通、差、超差、[-1,1])。
Key Term Extraction
输入是1篇文章等,输出是几个关键词。
Many to Many
Many to Many:输入和输出都是sequence,但输出更短
比如Speech Recognition。输入是1段声音信号,每隔1小段时间(通常很短,比如0.01秒)就用1个vector表示,输出是1段文字。因此输入是1个vector sequence,而输出是1个charactor sequence,并且输入序列要比输出序列短。
如果仍然使用Slot Filling的方法,就只能做到输入的每个vector对应输出1个character,输入1句“好棒”的语音后可能输出文字“好好棒棒棒”,但其实应该输出文字“好棒”。我们可以通过Trimming去除输出中相同的character,但语音“好棒”和语音“好棒棒”是不同的,应该如何区分呢?可以用CTC(Connectionist Temporal Classification),其基本思路是可以在输出中填充NULL,最终输出时删除NULL即可。

如上图所示,输入中vector的数量多于label中character的数量,那CTC应该怎么训练呢?答案是假设所有的可能性都是对的。
Many to Many
Sequence to Sequence Learning with Neural Networks:输入和输出都是sequence,但两者长度不确定。
以机器翻译为例,RNN要将英文的word sequence翻译成中文的character sequence(并不知道哪个sequence更长或更短)。
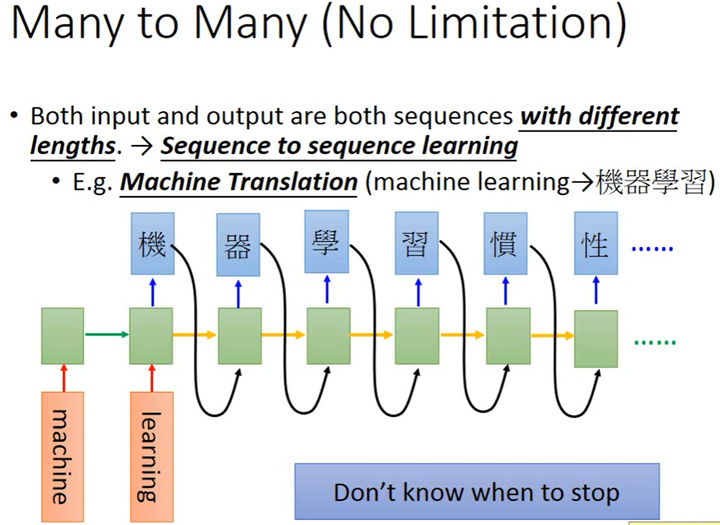
如上图所示,假设RNN的输入“machine learning”,在2个时间点分别输入”machine”和”learning”,在最后1个时间点时memory中就存储了整个word sequence的信息。接下来让RNN输出,得到“机”,然后把“机”当做input(这1步有很多极技巧,这里省略),并读取memory中的信息,就会输出“器”,以此类推,RNN会一直输出但不知道什么时候停止。那怎么让RNN停止输出呢?可以添加1个symbol===标志停止,当RNN输出这个symbol时就停止输出。
Seq2Seq for Syntatic Parsing
Grammar as a Foreign Langauage: 输入为1个word sequence,输出1个语法树(可以用sequence表示)。
Seq2Seq Auto-encoder for Text
如果用bag-of-word来表示1段文本,就容易丢失word之间的联系和语序上的信息。比如“白血球消灭了感染病”和“感染病消灭了白血球”这2段文本语义完全相反但bag-of-word是相同的。
A Hierarchical Neural Autoencoder for Paragraphs and Documents:可以使用Seq2Seq Autoencoder,在考虑语序的情况下把文章编码成vector,只需要将RNN作为编码器和解码器即可。
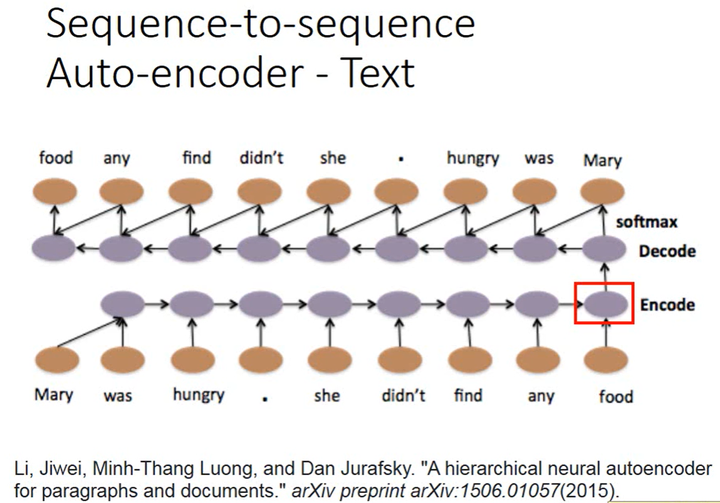
如上图所示,word sequence输入RNN后被编码成embedded vector,然后再通过另1个RNN解码,如果解码后能得到一模一样的句子,则编码得到的vector就表示了这个word sequence中最重要的信息。
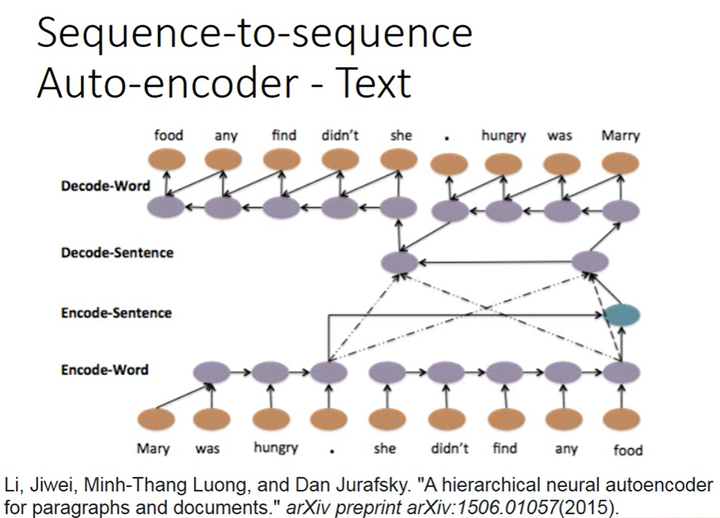
如上图所示,这个过程可以是分层的(hierarchical),可以将每1个sentence编码成1个vector然后将它们加起来得到表示整个document的vector,然后再通过它产生多个setence的vector,然后将多个setence的vector解码得到word sequence。这是1个4层的LSTM(word sequence-sentence sequence-document-sentence sequence-word sequence)。
Seq2Seq Auto-encoder比较容易得到文法的编码,而Skip Thought(输入1个句子,输出其下1句)更容易得到语义的意思。
Seq2Seq Auto-encoder for Speech
Seq2Seq Auto-encoder还可以用在语音上,它可以把1个audio segment(word-level)编码成1个fixed-length vector。这有什么用处呢?它可以基于语音之间的相似度做语音搜索。
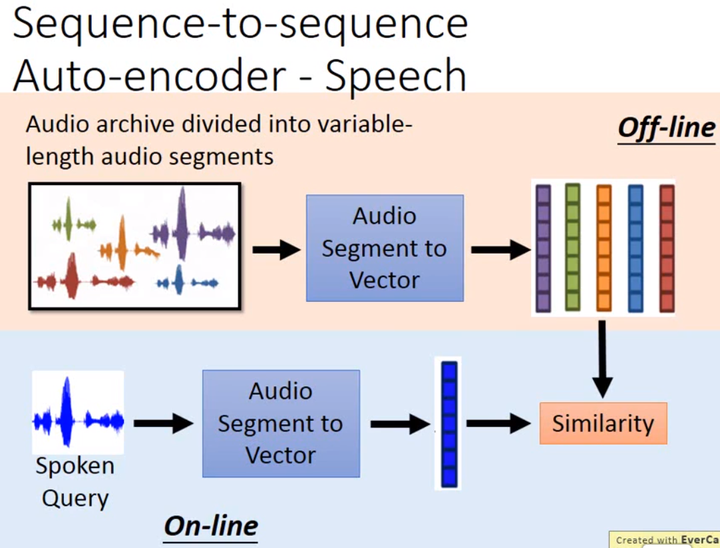
那如何基于语音之间的相似度做语音搜索呢?如上图所示,假如有1个语音的database,可将其划分为audio segments(长度可变),然后使用Seq2Seq Auto-encoder将其编码为1个fixed-length vector。对于1段需要搜索的语音,通过Seq2Seq Auto-encoder将其编码成1个fixed-length vector,计算其与database中audio segments的vector的相似度。
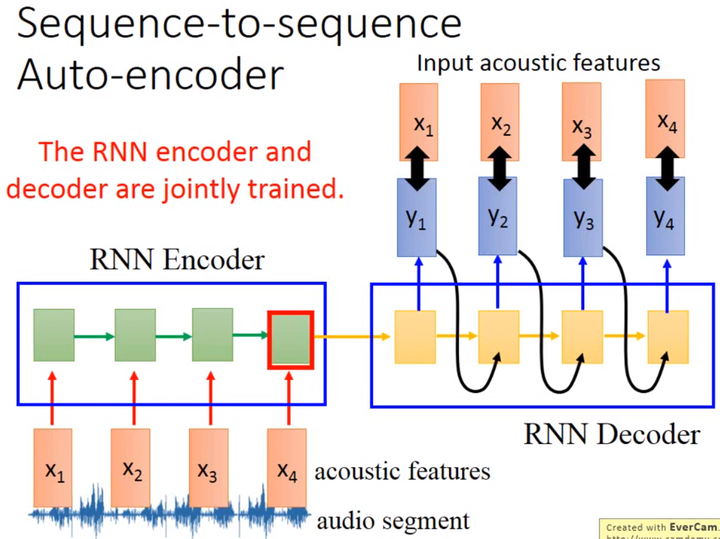
那如何把1个audio segment编码成1个fixed-length vector呢?如上图所示,首先把audio segment转换为acoustic feature sequence,然后输入至RNN。该RNN作为Encoder,在最后1个时间点其memory中的值就代表整个acoustic feature sequence,这就是我们想要的vector。但是只有这个作为Encoder的RNN我们没有办法训练,所以还要训练1个作为Decoder的RNN。该RNN作为Decoder,以Encoder在最后1个时间点时memory中的vector为输入,然后输出1个acoustic feature sequence,训练目标是输出的acoustic feature sequence和输入的acoustic feature sequence越接近越好。由此可知,该例中Encoder和Decoder是要同时训练的。
Attention-based Model
專家發現,小兒失憶現象是由於動物的大腦在神經新生的過程中,處於不斷重組的狀態,為減少太多訊息的干擾,會不斷清除舊記憶,從而增加對新事物的學習能力。年幼小鼠的記憶保留能力所以低下,乃因其高度活躍的神經再生所致,而成年小鼠保留記憶能力的增加,也由於其大腦相對成熟,海馬體的神經再生活力已經下降。腦科學家既然可以抑制年幼小鼠海馬體的高度活躍神經再生活力,又可刺激成年小鼠海馬體增加其神經再生活力。
——————引自http://henrylo1605.blogspot.com/2015/05/blog-post_56.html
现在除了RNN之外,Attention-based Model也用到了memory的思想。机器也可以有记忆,神经网络通过操控读/写头去读/写信息,这个就是Neural Turing Machine。
Reading Comprehension
Attention-based Model常常用在Reading Comprehension上,让机器读1篇document,再把每个setence变成代表语义的vector,接下来让用户向机器提问,神经网络就会去调用读写头,取出memory中与查询语句相关的信息,综合处理之后,可以给出正确的回答。
Visual Question Answering
Speech Question Answering
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!