Deep Dream
Deep Dream是这样的:如果给机器一张图片$x$,Deep Dream会把机器看到的内容加到图片$x$中得到$x’$。那如何实现呢?

如上图所示,将图片$x$输入到CNN中,然后取出CNN中某一层$L$(可以是卷积、池化阶段的隐藏层,也可以是FNN中的隐藏层)的输出$O$,然后将$L$中的正值调大、负值调小得到一个新的输出$O’$,然后通过梯度下降找到一张新的图片$x’$使层$L$的输出为$O’$,这个$x’$就是我们要的结果。直观理解的话,也就是让CNN夸大它所看到的内容。
然后就得到了如下结果……(看到的时候我惊了,真是十分哇塞)

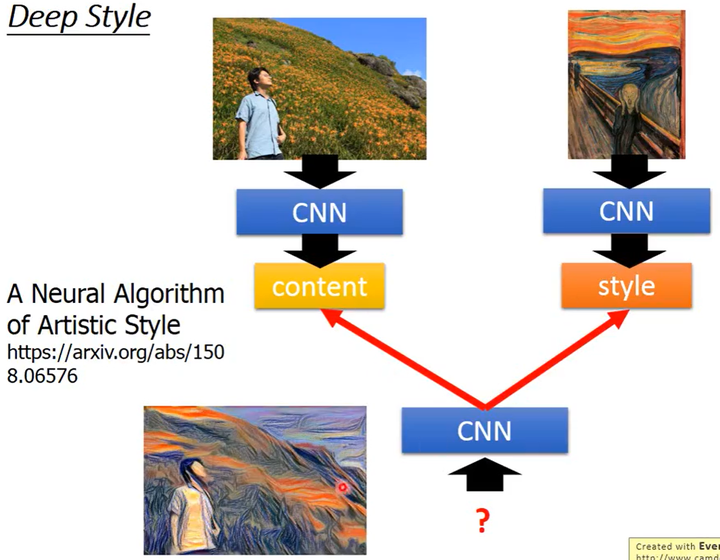
Deep Style
Deep Style是这样的:如果给机器一张图片$x$和$y$,Deep Style可以把图片$y$的风格加到图片$x$上,也就是风格迁移。
那如何实现呢?论文:A Neural Algorithm of Artistic Style。
- 把图片$x$传入CNN并得到输出,然后其输出作为图片$x$的内容$c_x$(content);
- 把图片$y$传入CNN并得到输出,但不是考虑输出的值是什么,而是考虑输出层中各个filter输出之间的相关性(corelation)作为图片$y$的风格$s_y$(style);
- 最后基于同一个CNN找到图片$z$,图片$z$传入CNN后得到的内容$c_z$像$c_x$、风格$s_z$像$s_y$。
如下图所示
围棋
CNN不单单可以用在图像上,还可以用在其它方面,比如下围棋。
在下围棋这件事上,其实FNN就可以(输入和输出都是19×19=361的vector),但CNN的效果更好。当然还可以用强化学习。
为什么CNN可以用来下围棋呢?因为围棋具有图像的3个性质,不过AlphaGo并没有用Max Pooling因为它不需要。
语音
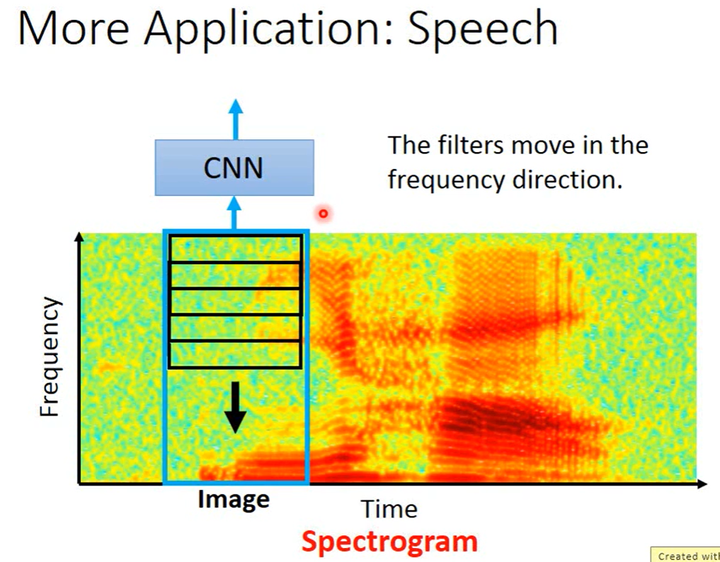
如下图所示,用语谱图(Spectrogram)表示语音。
语谱图的x轴是时间,y轴是频率,z轴是幅度。幅度用颜色表示(比如亮色表示高、暗色表示低)。
在语谱图中,CNN的卷积核往往只在y轴方向上移动,这样可以消除男生女生声音频率的差异;卷积核往往不在x轴上移动,因为时间域一般是在后面用LSTM等等进行处理,如下图所示。
文本
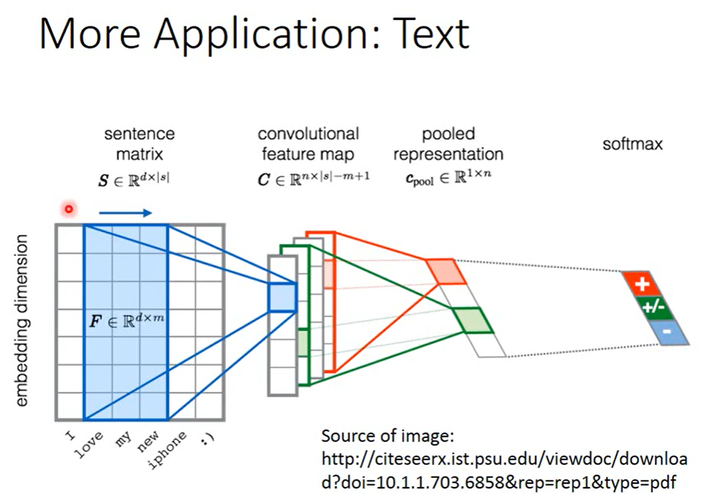
CNN也可以用在文字处理上,比如文本情感分析。具体不再讲,可以看李宏毅老师的视频。
图片生成
Deep Dream的方法还是不能画出图片,不过也有其它较为成功的方法,如下图所示。

Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!