[TOC]
为什么是“深度”神经网络?
问题与答案
矮胖的神经网络和高瘦的神经网络,假设它们参数量相同,哪一个更好呢?
2011年有一个实验,证明在参数量相当的情况下,高瘦的神经网络(即深度神经网络)的准确度更高,因为深度可以实现模块化。
只用一个神经元足够多的隐藏层,这个模型就包括了任意函数,那为什么不这么做呢?
这样确实可以包括任意函数,但实现的效率不高。
相关网址http://neuralnetworksanddeeplearning.com/chap4.html,也可以通过谷歌等找找其它答案。
“深度”的好处
模块化(Modularization)
就像写程序一样,我们不能把所有代码写在main函数里,而需要通过定义函数等方式将程序模块化。
如下图所示,假如要做一个图片的四分类,两个维度分别是头发长短和性别,如果使用矮胖的神经网络会遇到一个问题,就是短头发的女生样本和长头发的男生样本会比较少,那这两个类别的分类器就会比较差。
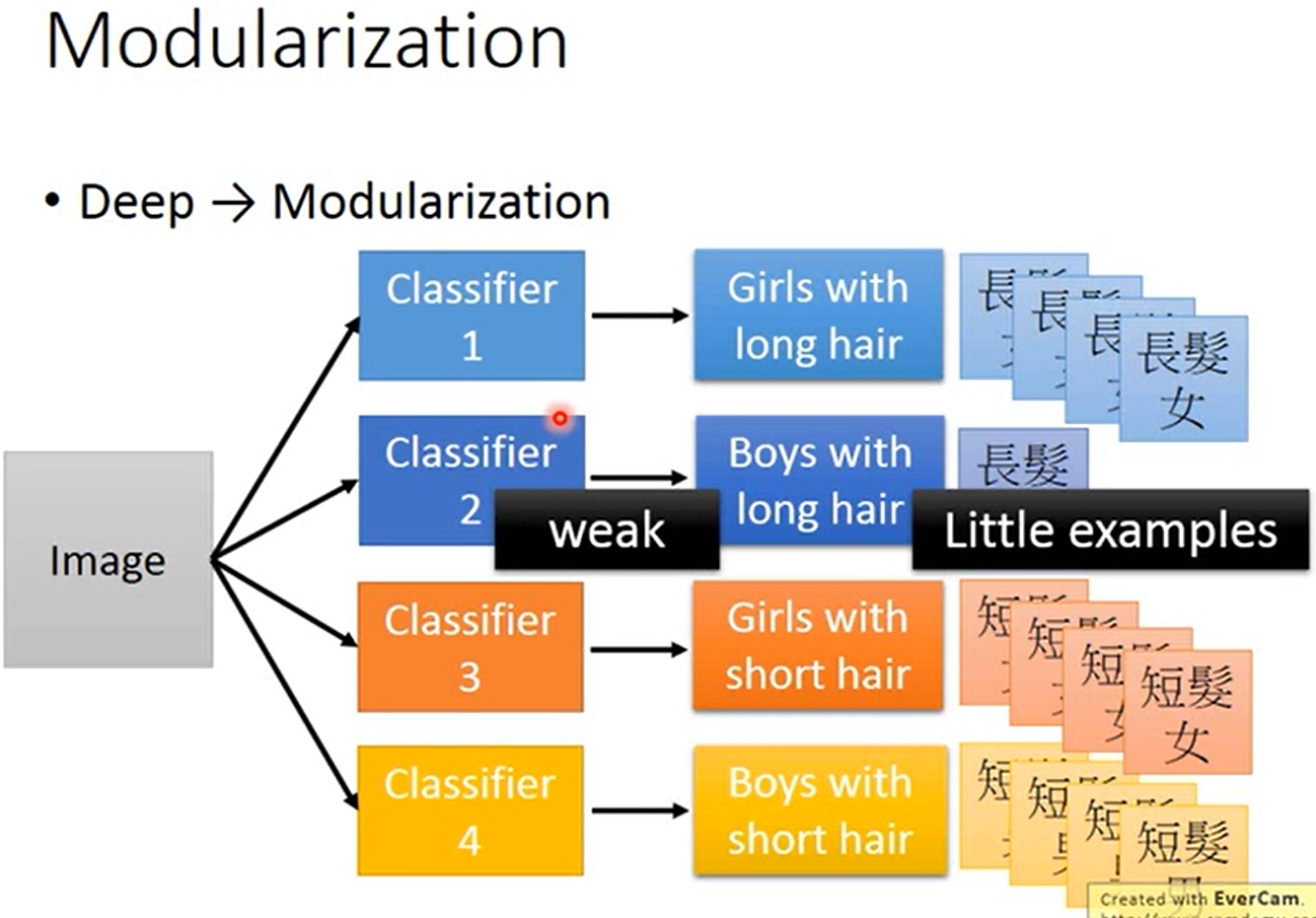
如下图所示,我们可以先定义各属性的分类器(Classifiers for the attributes),即先定义性别和头发长短的分类器,然后再做四分类。这样第一层分类器就不会遇到样本少的问题,第二层的分类器也容易训练,整体上也需要更少的训练集。
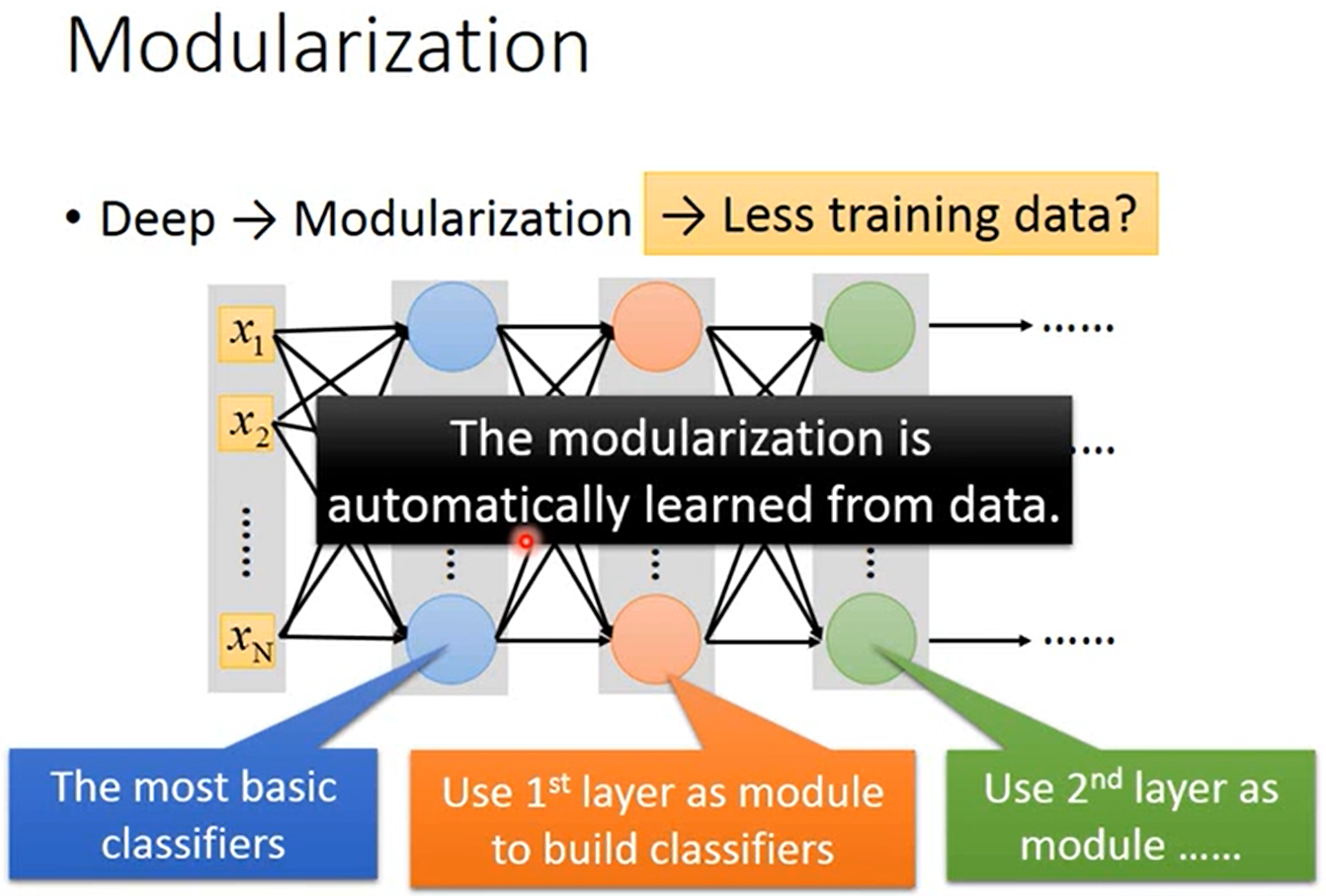
在深度神经网络中,每层网络都可以作为下一层网络使用的一个模块,并且这个模块化是通过机器学习自动得到的。
常有“人工智能=机器学习+大数据”的说法,但实际上“深度”使得需要的数据更少,如果数据集无限大,根本就不需要机器学习,只要去数据库里拿就好了。深度学习也并不是通过大量参数暴力拟合出一个模型,反而是在通过模块化有效利用数据。
这里只是一个图像分类的例子,“深度”产生的模块化在语音识别任务中也有体现,与逻辑电路也有相似的问题和结论,具体可以看李宏毅视频。
端到端学习(End-to-end Learning)
深度神经网络模型就像是把一个个函数串接在一起,每个函数负责某个功能,每个函数负责什么功能是通过机器学习根据数据自动确定的。李宏毅视频中有讲这一点在语音识别、CV任务中的体现。
处理复杂任务
有时类似的输入要输出差别很大的结果,比如白色的狗和北极熊看起来差不多,但分类结果非常不同;有时差别很大的输入要输出相同的结果,比如火车正面和侧面的图片都应该被分类成火车。
只有一个隐藏层的网络是无法处理这种任务的。李宏毅视频中有讲这一点在语音识别、CV任务中的体现。
其它
Do deep nets really need to be deep?
李宏毅视频里也还有很多关于“深度”的探讨。
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!